
For many years, those in the know in the tech world have known that “artificial intelligence” is a scam. It’s been true for so long in Silicon Valley that it was true before there even was a Silicon Valley.
That’s not to say that AI hadn’t done impressive things, solved real problems, generated real wealth and worthy endowed professorships. But peek under the hood of Tesla’s “Autopilot” mode and you would find odd glitches, frustrated promise, and, well, still quite a lot of people hidden away in backrooms manually plugging gaps in the system, often in real time. Study Deep Blue’s 1997 defeat of world chess champion Garry Kasparov, and your excitement about how quickly this technology would take over other cognitive work would wane as you learned just how much brute human force went into fine-tuning the software specifically to beat Kasparov. Read press release after press release of Facebook, Twitter, and YouTube promising to use more machine learning to fight hate speech and save democracy — and then find out that the new thing was mostly a handmaid to armies of human grunts, and for many years relied on a technological paradigm that was decades old.
Call it AI’s man-behind-the-curtain effect: What appear at first to be dazzling new achievements in artificial intelligence routinely lose their luster and seem limited, one-off, jerry-rigged, with nothing all that impressive happening behind the scenes aside from sweat and tears, certainly nothing that deserves the name “intelligence” even by loose analogy.
So what’s different now? What follows in this essay is an attempt to contrast some of the most notable features of the new transformer paradigm (the T in ChatGPT) with what came before. It is an attempt to articulate why the new AIs that have garnered so much attention over the past year seem to defy some of the major lines of skepticism that have rightly applied to past eras — why this AI moment might, just might, be the real deal.
Artificial intelligence pioneer Joseph Weizenbaum originated the man-behind-the-curtain critique in his 1976 book Computer Power and Human Reason. Weizenbaum was the inventor of ELIZA, the world’s first chatbot. Imitating a psychotherapist who was just running through the motions to hit the one-hour mark, it worked by parroting people’s queries back at them: “I am sorry to hear you are depressed.” “Tell me more about your family.” But Weizenbaum was alarmed to find that users would ask to have privacy with the chatbot, and then spill their deepest secrets to it. They did this even when he told them that ELIZA did not understand them, that it was just a few hundred lines of dirt-stupid computer code. He spent the rest of his life warning of how susceptible the public was to believing that the lights were on and someone was home, even when no one was.
I experienced this effect firsthand as a computer science student at the University of Texas at Austin in the 2000s, even though the field by this time was nominally much more advanced. Everything in our studies seemed to point us toward the semester where we would qualify for the Artificial Intelligence course. Sure, you knew that nothing like HAL 9000 existed yet. But the building blocks of intelligence, you understood, had been cracked — it was right there in the course title.
When Alan Turing and Claude Shannon and John von Neumann were shaping the building blocks of computing in the 1940s, the words “computer science” would have seemed aspirational too — just like “artificial intelligence,” nothing then was really worthy of that name. But in due time these blocks were arranged into a marvelous edifice. So there was a titter surrounding the course: Someone someday would do the same for AI, and maybe, just maybe, it would be you.
The reality was different. The state of the art at the time was neural nets, and it had been for twenty or thirty years. Neural nets were good at solving some basic pattern-matching problems. For an app I was building to let students plan out their course schedules, I used neural nets to match a list of textbook titles and author names to their corresponding entries on Amazon. This allowed my site to make a few bucks through referral fees, an outcome that would have been impossible for a college-student side hustle if not for AI research. So it worked — mostly, narrowly, sort of — but it was brittle: Adjust the neural net to resolve one set of false matches and you would create three more. It could be tuned, but it had no responsiveness, no real grasp. That’s it?, you had to think. There was no way, however many “neurons” you added to the net, however much computing power you gave it, that you could imagine arranging these building blocks into any grand edifice. And so the more impressed people sounded when you mentioned using this technology, the more cynicism you had to adopt about the entire enterprise.
All of this is to say that skepticism about the new AI moment we are in rests on very solid ground. We have seen “this AI moment is real” moments over and over and over going back as far as the 1950s. In spirit it traces back to the Mechanical Turk, a supposed automaton built in 1770 that played chess at an advanced level, but worked only because hidden away inside it was a human player working its gears, a literal man behind the curtain.
Several aspects of our current AI moment do deserve to remain on that skeptical ground. Some observers see consciousness in ChatGPT or sentience in Midjourney; they are deceived. The subject of central fixation in the tech world right now is existential risk: AI that takes over the world and destroys the human species. It’s right to worry about this, but as of yet it is still difficult to imagine a plausible path from the new class of AI to a Skynet scenario. Too much focus on this worry risks downplaying somewhat less apocalyptic but more likely scenarios of social disruption, like dramatic upheavals in jobs. Finally, hype and alarmism about AI will inevitably be used to advance stupid, self-interested, or beside-the-point pet causes. We are already seeing a push to follow the Tech Backlash playbook and frame AI as a “misinformation problem,” a “disparate impact problem,” a “privacy problem.” All of these are limited frameworks for defining this class of AI, and will need to be resisted as such.
But on the whole, it may be time to abandon deep skepticism and seek higher ground. The titter in the air is back, and a great many people feel it now: Something about this moment really does feel different. For once, they may have good reason to feel this way.
Here are a few reasons why.
The single most notable feature of the new class of AI is just how many different things it can do, and do to a level that, even if we don’t feel a full human imitation has been achieved, at least causes us to feel we are confronting a serious rival.
All past AI paradigms, whatever remarkable things they have achieved, have ultimately been specialized in scope. Even if Tesla’s autonomous driver is one day fully ready for the road, there is no set of basic tweaks that will allow it to run an air-traffic control center or ace the MCAT. But transformers offer just this sort of open-ended promise.
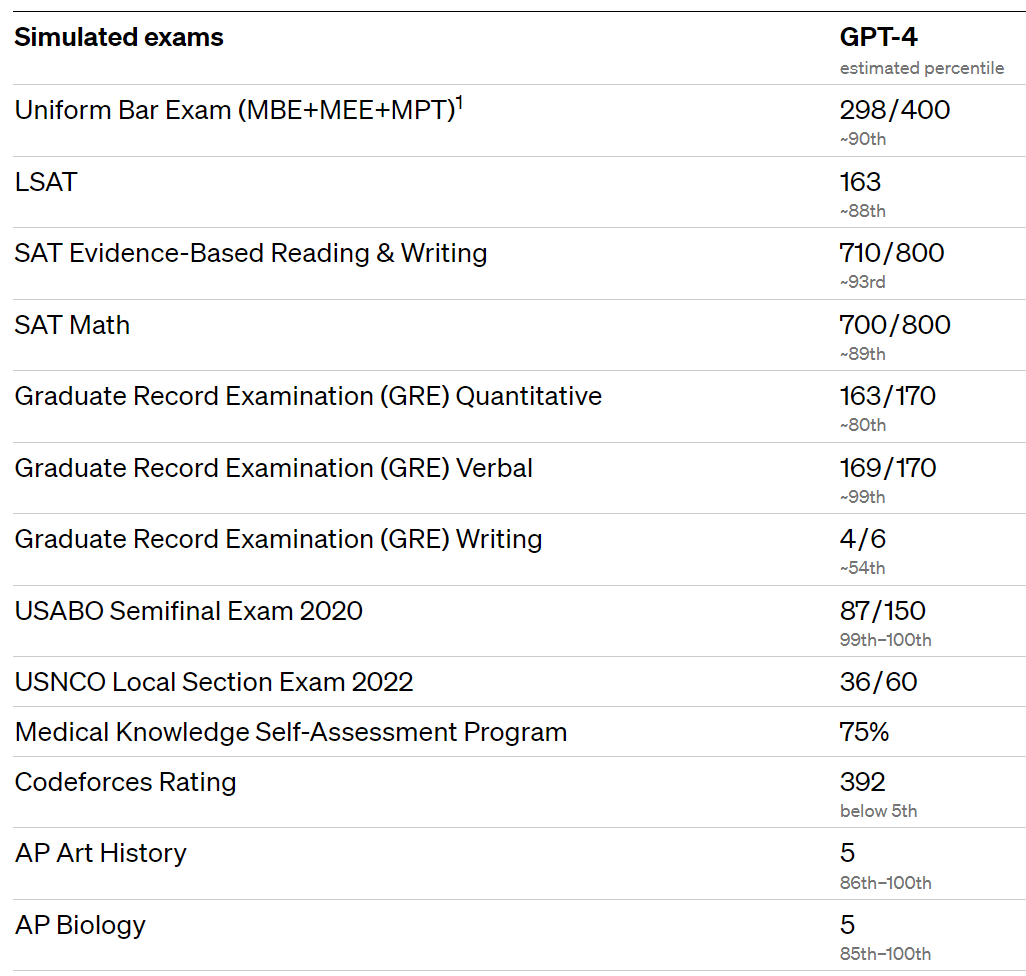
As we will see, the new class of AI techniques are best understood not as a disparate jumble but a new technological paradigm, perhaps even a single continuous technology. But since ChatGPT occupies such a large amount of our attention right now, we can recognize the point even just by looking at this single realization of transformers. GPT-4 has passed nearly every major standardized academic test at remarkable levels, achieving scores in the 80th or 90th percentile on nearly every one:
One programmer used AutoGPT, an extension of ChatGPT, to create a basic, useable social media app in under three minutes.
Go ahead — ask it to offer you a tutorial to apply for a U.S. green card, talk to you like a ‘90s valley girl, or write a formally correct Shakespearean sonnet. Or ask it to offer you a tutorial on how to apply for a U.S. green card using ‘90s valley-girl language and in the form of a Shakespearean sonnet. It may not offer the best, funniest, or most beautiful possible response to any of these questions, but it will offer something fairly persuasive for all of them. This is a novel and remarkable feat.
Just as significant are transformers’ persuasive facility with natural languages — meaning not code or math but everyday speech: English, Arabic, Mandarin.
A convincing imitation of natural language comprehension, demonstrated through written question-and-answer exchanges, has been a holy grail of AI since Alan Turing proposed it in 1950. In some sense, most of us have already interacted with computers in this way for a long time. Instead of typing in, say, “alternator replace manual elantra,” many of us will ask Google this question:
how to replace alternator hyundai elantra
Or even:
How do I replace the alternator on my Hyundai Elantra?
But most of us also know that Google will handle all three queries using the same basic techniques of simple keyword association. And we know that the structural cues of a complete English sentence, which make the last query so much easier for us to write and read, don’t make a difference to the machine.
Some years after my undergrad education in computer science, I worked as, if you can believe the title, an Ontological Engineer on the Cyc project (pronounced like “psych”) in Austin, Texas. Cyc is a rarity: a project that has endured since the era of symbolic AI, which began the field in the 1950s and dominated for four decades. To many in the field, that makes it an odd holdover.
From the earliest days of AI, researchers found that it was very easy to get computers to “understand” mathematical language, and so to mimic the way people do mathematical reasoning, and in some cases do it much more efficiently. But it was very hard to get computers to do the same thing for natural languages.
Cyc wants to solve this problem. Its grand goal is nothing less than to capture the knowledge that is stored in human speech, to build a library of the world. It doesn’t just want to store that knowledge in words people can understand, as Wikipedia does. It wants to actually capture the structure of natural language, so that Cyc itself can reason about the world.
Cyc is considered quixotic by its peers, because it has stuck with trying to model the world even as the field has moved on to a statistical approach that favors raw association and brute computing force. But there is a reason Cyc has persisted for so long: there are many things it can do that newer systems couldn’t. For one thing, even though the statistical approaches that began to dominate in the 1990s solved more and more problems, typically even researchers could not explain why they had arrived at the answers they gave. But Cyc’s approach is explicit. It can explain its reasoning in intricate detail, presenting it in a form that people can check and engage with.
And Cyc can do deep reasoning.
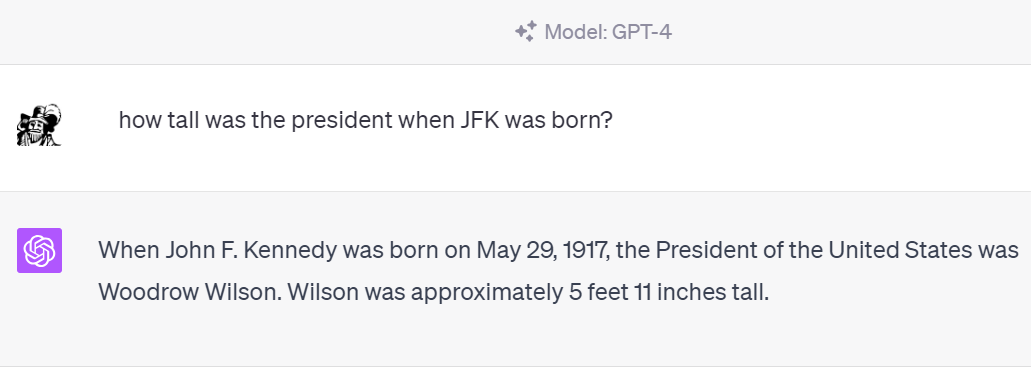
For instance, if at that time you asked Google or WolframAlpha, a much-celebrated answer engine, a question like this —
How tall was the president when JFK was born?
— they would usually spit back this answer: 49 feet. With the full data of the Internet at its disposal, Google was good at finding the likeliest associations between the terms “tall,” “JFK,” and “born,” but the likeliest association was the elevation of Brookline, Massachusetts, the town where John F. Kennedy was born.
This was the power and the limit of AI based on raw association among massive amounts of data. The grammatical structure that would allow a human being to easily pull apart the nested, dependent layers of the question, and to realize that the sentence was asking after the person who was president in 1917, not 1961, was beyond the power of the statistical state of the art. The popular search-and-answer engines of the day were really only an improvement by degrees from Ask Jeeves, the 1990s search engine that became a punchline.
Cyc can beat this problem. You can put this same query to it and get the correct answer: 5’11”, the height of Woodrow Wilson. “Google’s 70 billion facts can answer 70 billion questions,” writes Doug Lenat, the mastermind behind the project, “but Cyc’s 15 million rules and assertions can answer trillions of trillions of trillions of queries — just like you and I can — because it can reason a few steps deep with/about what it knows.”
But there are catches. Yes, the requisite facts about the world can all be explicitly stored in the system: generalized propositions, like that all human beings have a height and a place of birth, and that all presidents have a beginning and ending date of their presidency; and specific facts, like JFK and Woodrow Wilson’s birth year, height, and dates of administration. But these are stored in a symbolic, logical language that doesn’t have the same easy readability of natural language. This means that some work is required of a user to translate the structure of the sentence in her head into the explicit symbolic grammar of the system — much as it takes an extra step to translate the sentence “Mary has two apples” into the equation “M = 2.”
And truly Herculean work was required of the engineers to put all of that knowledge into the system in the first place. That was the job of the army of Ontological Engineers, of which I was a grunt, contributing a tiny share of the 2,000 person-years the company says have been spent building its reasoning library. It was a fascinating project, especially to obsessive organizers and analyzers like myself, a Jorge Luis Borges story come to life. I was engrossed by the task of working out the system’s kinks, and I believed it could accomplish great things. But I never felt that it would challenge humanity’s unique rational status, any more than computers that could solve equations did. To their credit, I never heard the project engineers say that it would either.
So what about ChatGPT? The latest version dispenses with these kinds of queries with apparent ease. Moreover, the entire exchange plays out directly in natural language:
The next thing we must recognize about Large Language Models is their facility with context. This is integral to their abilities with natural language.
Consider again the question above about JFK. In order to grasp it, ChatGPT must fill in a lot of information we have left unstated. Notice, for example, that “president” could mean many different things, but that it inferred correctly that we meant “president of the United States” rather than “president of Mexico” or “president of the Ironworkers Union,” and that it made this inference without having to ask us to clarify.
This type of contextual information is so deeply embedded in human conversation that we rarely notice it. But it has long been the Achilles heel of AI.
In the 1960s, the philosopher Hubert Dreyfus, one of the earliest and most vocal critics of the AI project, noticed the ironic fact that researchers had found it easier to get computers to perform supposedly high-cognition tasks than low-cognition ones. Computers could prove mathematical theorems and play chess, but when presented with children’s stories a few sentences long and asked questions about them, they were easily beaten by four-year-olds. The elite, rule-bound, abstract intelligence that engineers admired in themselves was already rather computer-like, while universal human capacities for real-world cognition were elusive for AI.
Dreyfus argued that AI might be doomed to falter on tasks that highly depended on context that was unstated, and perhaps unstatable. He was influenced by the work of Ludwig Wittgenstein, who asked, as Dreyfus put it, about “the kind of issue which would arise if someone asked whether the world hasn’t started only five minutes ago.” The kinds of questions that have to be answered in order to satisfy us that this is not the case — that the world did not just begin five minutes ago — have no natural end. It would be impossible to say much of anything about anything if we had to resolve this sort of doubt before we spoke. But most of us also do not walk around with the sentence “The world is more than 5 minutes old,” and an associated train of justification, already lurking in our heads somewhere and ready to be called up at a moment’s notice. Rather, that the world must have been around for some time is implicit in our posture, our stance toward the world. The specific ideas that could be grounded in that posture are infinite, impossible to fully encode. We can only get a real grasp on the world — the kind that would allow us to make sense of a request to answer questions about a children’s story, stack a red block on a blue one, or reason about the heights of presidents when other presidents were born — from the sure footing of a posture we largely don’t notice. People have a posture and computers don’t.
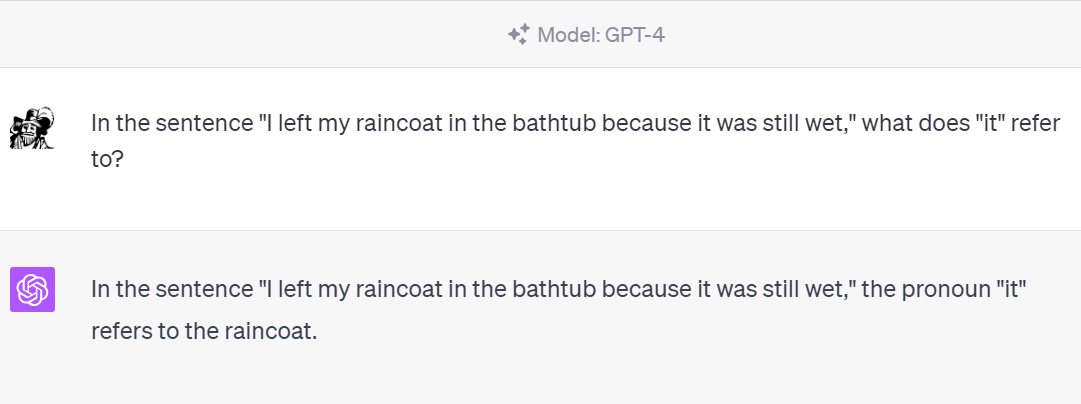
Here is an example of the kind of problem where context is especially important. Consider this sentence:
I left my raincoat in the bathtub because it was still wet.
What is “it”? The raincoat, the bathtub, or something else?
In an ordinary household conversation, say, amid the hurry of getting dinner ready, nearly everyone will grasp what “it” refers to. And we will do so implicitly, without having to stop and put the puzzle pieces together. That is because your posture toward the world includes tacit grasp of a number of relevant relationships that, if a situation called for it, we could put into words:
And so on. These are better thought of as implicit elements of your posture, rather than explicit elements of your library of knowledge, because most of these are things you know without ever having explicitly had to think them out in those terms, unlike the way you once had to memorize that Abraham Lincoln was from Illinois. All of this goes into your ability to disambiguate the sentence, without thinking about it, when you hear it.
So a very important thing to admire about ChatGPT is that it can typically handle this sort of sentence correctly:
Another example:
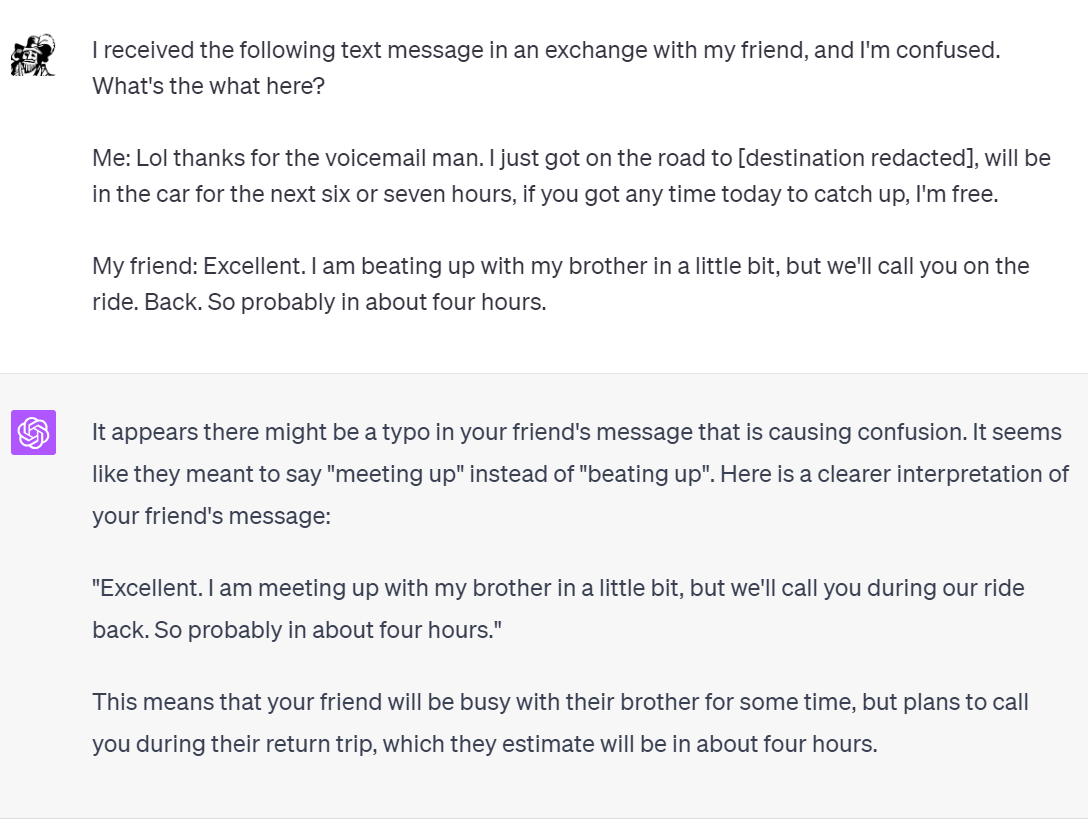
An exercise: List everything the AI grasped that I didn’t tell it.
Already, ChatGPT is notorious for certain limitations. It contradicts itself and makes things up. It will produce bibliographies of sources that don’t exist. Far from seeming obsolete, Cyc may well be sitting pretty: designed for applications where perfectly clear, reliable reasoning is paramount, it retains a distinct advantage, one that may seem all the more valuable as the world ever more grapples with AI hallucinations.
And yet: that AI now has this problem at all is remarkable. ChatGPT is better at b.s.ing than at saying the plain truth. It is more the student trying to impress than the learned professor telling it like it is, more slick pundit than coolly rational Mr. Spock. But which sort of intelligence is more familiarly human? As Mark Halpern wrote in these pages in 2006:
what Turing grasped better than most of his followers is that the characteristic sign of the ability to think is not giving correct answers, but responsive ones — replies that show an understanding of the remarks that prompted them…. The belief that a hidden entity is thinking depends heavily on the words he addresses to us being not re-hashings of the words we just said to him…. By this criterion, no computer, however sophisticated, has come anywhere near real thinking.
Is this last sentence still true? Yes, ChatGPT does not have the full capacity for closed reasoning found in Cyc — the ability to describe the entire chain of logic behind an answer, and the cold rational trustworthiness that comes along with this. But what it can do is make implicit context explicit, and attempt to correct itself (often imperfectly) when its errors are noted. It displays an open-ended capacity to respond. It can account for itself.

Previous AI systems have either not been able to handle ambiguity problems of the JFK or raincoat variety, or have done so only through Herculean feats of explicit encoding, logic, and world-modeling. Yes, the key learning processes have required a great deal of fine-tuning and human sweat to get right. But the public descriptions of ChatGPT suggest that it functions largely by lacking much ontology — that is, a structured, explicit account of the world, of the kind I once helped refine. It does not work by hiring armies of engineers who exhaustively enter facts about the world over decades.
What we see suggests that ChatGPT handles problems of ambiguity and context through inferential skills that, at least considered from above the hood, bear a family resemblance to the skills we find in our own experience of natural language. It displays an open-ended, flexible, implicit orientation to the world that we would ordinarily deem a posture. And this posture seems to permit what we would ordinarily deem a grasp.
If so, this is a first in the history of AI.
Some key features of how transformers work under the hood help to flesh out what we are seeing above the hood.
They can work from a trivial footprint of code, memory, and processing. A helpful New York Times article demonstrated the basics of Large Language Model training by creating what it called BabyGPT: an LLM that ran entirely on an ordinary laptop computer, started with no understanding of the world, trained on data sets so small they could be attached to an email, and completed its training in a few hours. One BabyGPT trained on the complete transcripts of Star Trek: The Next Generation, building a chatbot to produce new episode scripts; another trained on the corpus of Jane Austen and aimed to produce new Austen snippets; and so on. The results, though not as convincing or responsive as ChatGPT, were in the same ballpark of ability.
In another example this year, Google’s DeepMind project trained small humanoid robots to play soccer. That feat had been done before, but this time it was done without programming and intricate guidance from human engineers. Instead, the robots were given a single instruction — to score — and then, through a series of trial-and-error simulations, learned on their own the strategies to win. Here too, the new class of AI has managed to arrive at the abilities of prior AIs far faster, simpler, and more cheaply.

A similar point applies across a broad range of other applications. Even with trivial computing resources, transformers have proven able to get meaningfully close to the dazzling abilities of the ChatGPT and Midjourney big boys. And they have been able to replicate tasks that had been achieved by earlier generations of AI but only with enormous expenditures of computing and custom programming — think again of the supercomputer and large research team that went into Deep Blue’s defeat of Garry Kasparov. Transformers make cheap homebrew versions of that kind of feat newly possible, and greatly expand what they can do.
They all work in more or less the same way. As Tristan Harris explains in his talk “The AI Dilemma,” all the transformers we are seeing — ChatGPT, Midjourney, deepfake software — work from the same generalized principle. They translate the phenomenon they want to manipulate — text, sound, images, video, radio waves, heat measurements — to an encoding that manipulates natural language.
There are remarkable practical implications. But even more importantly: AI research was once ghettoized into a series of discrete fields — vision processing, image processing, natural language processing, and so on. Transformers are unifying these fields into a single research paradigm. This means that every breakthrough in one field becomes a breakthrough in the others, that every major new text dataset being learned can advance the comprehension abilities of vision AIs and vice-versa.
If Harris is right, we are in the first years of a new Age of Discovery for artificial intelligence, the equivalent of the discovery of the New World.
The key conceptual breakthroughs were not complicated. Most of the remarkable breakthroughs we are witnessing right now trace back to just a few key theoretical innovations published over the last six years.
For example, many observers have argued that ChatGPT is “glorified autocomplete.” This is a mistake, as anyone who has used conventional autocorrect or voice-to-text technology should recognize. Under the hood, conventional auto-complete technology of the last twenty years has worked by generating text one character or a few characters at a time. It looks at a partially completed text and, based on a statistical analysis of its training data, predicts the likeliest next character. Then it starts the process over based on the new, slightly larger text. The training itself works in a similar way.
Using this method, conventional language models have been limited in how fast they can run. More importantly, their grasp of context has been limited: The method offers little ability to recognize how a word’s meaning varies based on its position in a sentence, a key function of grammar. One of the key breakthroughs was to treat a word’s position in a sentence as part of the training data, something the language model must directly learn and predict.
This, along with a small number of other key innovations, have been the cornerstones of the dramatic improvements in AI we are now witnessing. However hard won, these advances ultimately arise from a handful of “one weird tricks,” with a lot of tinkering and ironing of wrinkles needed to make these insights more than just proofs of concept.
What do these three features mean? In past AI advances, we have seen one of two things when we look under the hood. One is that the magic dissolves: like ELIZA, the apparent abilities themselves are not real. The other is that the abilities are real but much more brittle, inflexible, and narrow in scope, and more demanding of human effort than we might at first hope.
But now we witness a set of techniques that are flexible, implicit, and general realizing a set of abilities that are flexible, implicit, and general. This should give us significantly more confidence than we have had in the past that the abilities we’re seeing are not a cheap trick.
Do transformers have a grasp of the world, or a posture toward it — or at least a persuasive imitation of the same?
Answering “yes” would help to make sense not just of the way the new AIs succeed, but also the ways they fail. Among other things, it would help to make some sense of the uncanny features that linger in the new flood of AI-generated images, audio, and video. Yes, much of this material still seems eerie, unnatural, inhuman. People in Midjourney images notoriously still have too many teeth or fingers, warped faces, funhouse smiles. An AI-generated beer commercial looks like a horrifying Banksy parody of American consumerism, if Banksy had talent.
But these kinds of errors seem hard to make sense of as mistakes of logic. They are easier to make sense of as a system working out the right place for parts among a coherent whole, and still making some mistakes of integration. They feel, in short, like elements lost in translation, the kinds of mistakes we would expect across the wide gulf between us and an agent who is not only not native to our language but not native to our bodies or our lifeworld, and yet who is making genuine strides at bridging that gulf. They seem like the mistakes less of a facile imitation of intelligence than a highly foreign intelligence, one who is stumbling toward a more solid footing in our world.
The savvy observer has been burned many times before. He knows what it’s like to believe the AI magic show, only to have the curtain pulled back and the flimsy strings yanking the puppet revealed. It is also true that transformers are not conscious, and so not intelligent in the full sense of the word. But is that a good enough reason to deny what seems evident with our eyes? There is more than dazzling appearance at work in our sense that this AI moment is different.
It is also true that the commentariat has a poor recent track record of buying digital hype. Consider the mainstream backlash to social media of the past decade. It has always offered an at once gullibly alarmist and gullibly rosy picture of digital tech.
The Tech Backlash story has asked us, for example, to believe that Facebook’s ad targeting is so psychologically powerful that it is essentially a form of mass mind control. Like a Manchurian Candidate fantasy made real and scaled up to the entire Western populace, social media offers such robust targeting that it is said to have brainwashed half the country, put Donald Trump into office, and severed the British Isles from the Continent. This is a terrific story — a good yarn for bestsellers, earnest TED Talks, and multimillion-dollar indulgence grants from tech companies eager to show they’re doing their part to save democracy. The problem is that there has never been any evidence it is true, that Mark Zuckerberg knew anything more than Madison Avenue ever did about how to make consumers buy products they don’t want.
Exhausted by science and tech debates that go nowhere?
And yet for all the anger of the Tech Backlash, it always offered an implausibly sunny view of how easy the problem would be to fix. Improve privacy standards, muckrake out the wrongthinking tech CEOs and replace them with new ones committed to socially conscious views, add transparency to the ad systems and equity patches to the feed algorithms, and the problems would be solved. The hyperbole of the Tech Backlash actually let Big Tech off the hook, locking us into a mindset where the problem was a corrupt implementation of technology rather than corrupt technology full stop. This has been a boon for tech companies, who, instead of facing the existential threat of a public that saw their product as a new form of opioids, got away with a “we’ll do better” rehash of Standard Oil.
It is too early to say that the new AI class is an inherently antihuman technological paradigm, as social media has proven itself to be. But it is not too early to suspect that AIs will dwarf social media in their power to disrupt modern life. If that is so, we had better learn some new and unfamiliar ways of interrogating this technology, and fast. Whatever these entities are — they’re here.
More from the Summer 2023 symposium
“They’re Here… The AI Moment Has Arrived”

Notifications
